En el amplio mundo de las bases de datos, encontramos que lo que se repite es muy repetitivo. Bueno, en muchas ocasiones es inútil. Sin embargo, encontramos que en las consultas SELECT que hamos visto hasta ahorita es posilbe tener muchos registros con el mismo valor.
Por ejemplo, supongamos que un chavo tiene una base de datos para controlar sus citas amorosas. Este galán va a salir con una chica que acaba de conocer en el último concierto del grupo musical "Los asesinos del ritmo" y quiere apantallarla, por lo que no quiere ir a ninguno de los lugares donde ha ido con sus otras queridas (no vaya ser que lo cachen en la movida, jeje). En su tabla de Citas almacena, entre otras cosas, el lugar donde tuvo lugar cada cita. Por lo tanto, si hace un SELECT común y corriente para ver todos los lugares, obtendría algo así:
SELECT Lugar FROM Citas
 ¿Es útil esta información? Sí, pero puede mejorar. Lo puedo ordenar agregando un ORDER BY para obtener also así:
¿Es útil esta información? Sí, pero puede mejorar. Lo puedo ordenar agregando un ORDER BY para obtener also así:
SELECT Lugar FROM Citas ORDER BY Lugar
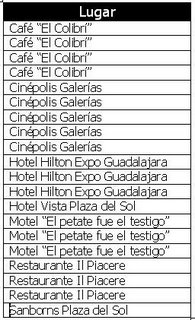
Esto es un poco más fácil de comprender, pero de todos modos hay mucha repetición. Sería más útil y menos aburrido si pudiéramos quitar todos los duplicados de mi consulta. Para eso tenemos la poderosa cláusula DISTINCT que podemos ponerle a nuestras consultas para dejar los datos tal y como los quiero. Vamos escribiendo esto:
SELECT DISTINCT Lugar
FROM Citas
ORDER BY Lugar

¡Listo! Ahora si esto es tan útil para un galán, ¡imagínate para un usuario simple y mortal de un sistema que hagas! Recuerda que si dominas el SQL, podrás dominar el mundo. Bueno, tal vez exageré un poco.
Por ejemplo, supongamos que un chavo tiene una base de datos para controlar sus citas amorosas. Este galán va a salir con una chica que acaba de conocer en el último concierto del grupo musical "Los asesinos del ritmo" y quiere apantallarla, por lo que no quiere ir a ninguno de los lugares donde ha ido con sus otras queridas (no vaya ser que lo cachen en la movida, jeje). En su tabla de Citas almacena, entre otras cosas, el lugar donde tuvo lugar cada cita. Por lo tanto, si hace un SELECT común y corriente para ver todos los lugares, obtendría algo así:
SELECT Lugar FROM Citas
 ¿Es útil esta información? Sí, pero puede mejorar. Lo puedo ordenar agregando un ORDER BY para obtener also así:
¿Es útil esta información? Sí, pero puede mejorar. Lo puedo ordenar agregando un ORDER BY para obtener also así:
SELECT Lugar FROM Citas ORDER BY Lugar

Esto es un poco más fácil de comprender, pero de todos modos hay mucha repetición. Sería más útil y menos aburrido si pudiéramos quitar todos los duplicados de mi consulta. Para eso tenemos la poderosa cláusula DISTINCT que podemos ponerle a nuestras consultas para dejar los datos tal y como los quiero. Vamos escribiendo esto:
SELECT DISTINCT Lugar
FROM Citas
ORDER BY Lugar

¡Listo! Ahora si esto es tan útil para un galán, ¡imagínate para un usuario simple y mortal de un sistema que hagas! Recuerda que si dominas el SQL, podrás dominar el mundo. Bueno, tal vez exageré un poco.


1 comentario:
Solo pasando por aqui
Está chido el blog, Tony
Publicar un comentario